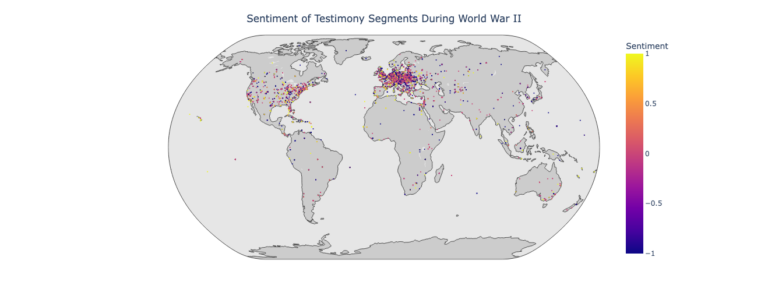
Geographies of Affect–Place and Sentiment in Holocaust Testimonies
Contemporary sentiment analysis tools lack the level of nuance and dedication to detailed description that Boder exhibited. Sentiment analysis tools are limited in multiple dimensions, including inabilities or ineffective accounts for tone, sarcasm, negations, comparatives, and multilingual data, and these weaknesses are enhanced especially when applied to complex texts in digital humanities. For this capstone project we tested different implementations of sentiment analysis to compare their affordances and limitations. I compared GPT-3 with GPT-2 and GPT-2 Fine tuned. I then mapped the results to visualize the geographic distribution of sentiment before during and after World War II.Read More

Advanced Googling It
I this online workshop I introduced artists, academics and activist to tools for finding digital resources and scraping data for research purposes.Read More
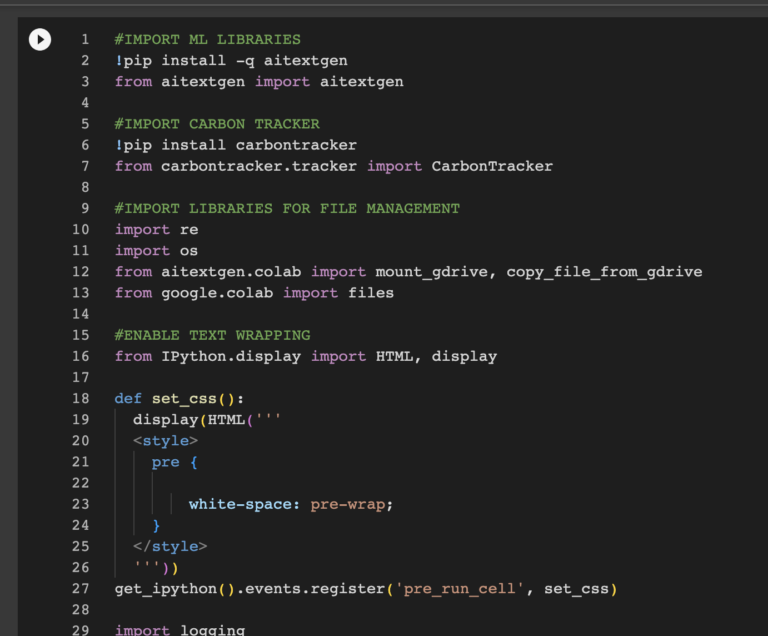
Introduction to Text Generation with Large Language Models
In this short course on text generation with large language models I introduce students to the basic concepts surrounding transformer models and how they differ from previous approaches to language generation. I also introduce students to concerns surrounding training data, biases, and the energy costs of training large models. In the hands on component of the workshop, I guide students through a python notebook that introduces them to concepts such as prompt engineering, fine turning and methods for studying biases in text generation output. The notebook is structured in a way as to not require knowledge of python to complete, while still giving students a deeper understanding of how text generation models work. Read More

Revisiting Schiaparelli’s Martian Canale
For Geography 181A (Intermediate GIS) I conducted an analysis of Giovanni Schiaparelli’s historic maps of Martian Canale. In this speculative project, Georectified Schiaparelli’s historic maps and combined them with contemporary remote sensing data regarding conditions on the Martian surface to identify suitable landing sites to study Schiaparelli’s Canale. Read More

Feature Extraction
Feature Extraction was a two day intensive symposium that introduced the public to the ethical and political dimensions of machine learning through hands on workshops.Read More